Jetson nano部署ASR语音识别
因为一个项目有要求边缘设备语音检测的,所以尝试部署。
一、前言
因为一个项目有要求边缘设备语音检测的,所以尝试部署。
二、环境安装
安装onnxruntime
下载包,不能直接pip install,会报错,直接去官网下载
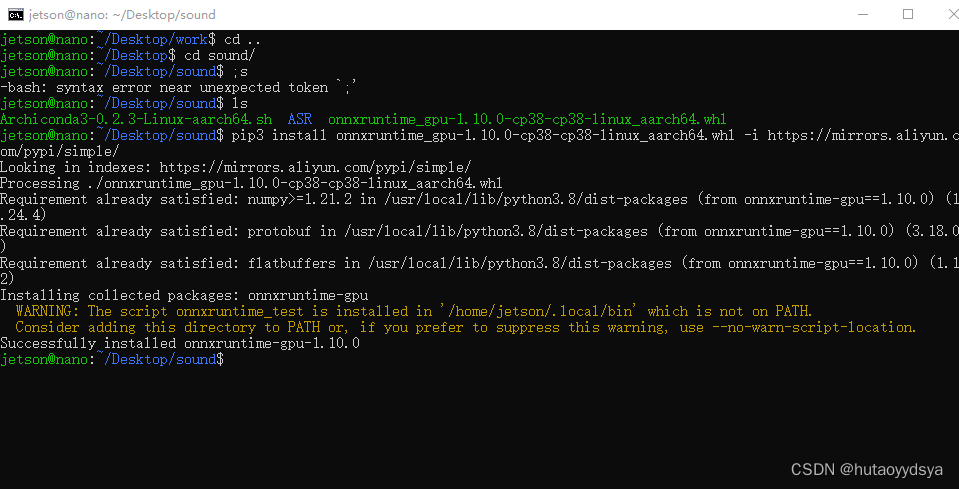
安装torch,在我另一篇博客有写:传送门
剩下就缺啥装啥
运行demo,成功!
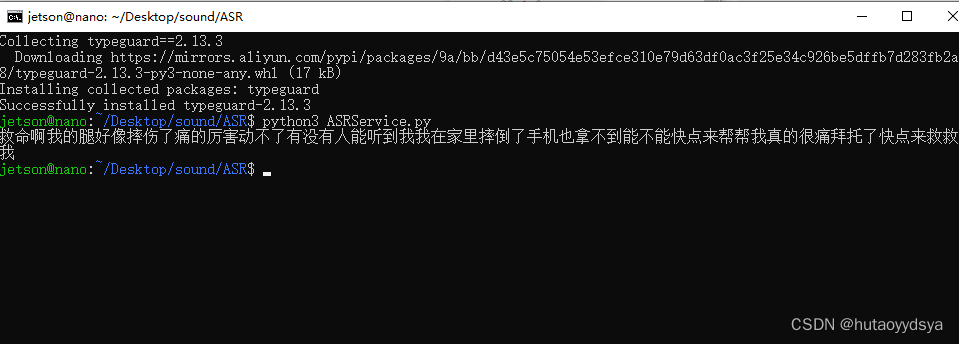
添加显示执行时间代码查看能不能实时检测
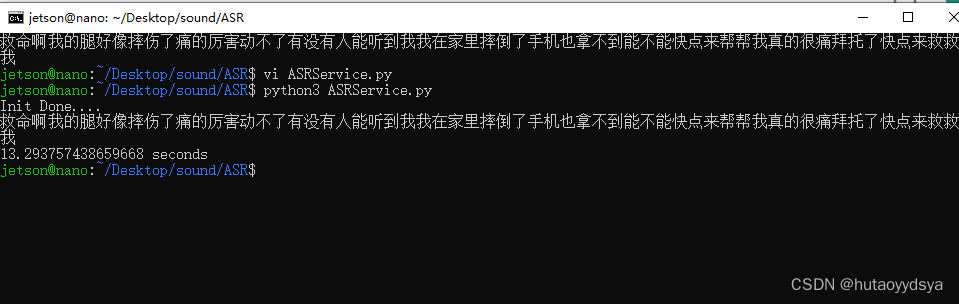
音频时长18s,检测时间13s,可以用于实时检测。
三、实时检测
语音识别和图像检测不同,视频可以以帧为单位,进行检测,每一帧都是一张图片;而语音没有帧这一概念,假设识别的时候如果以一帧为单位,能识别出啥呢?所以,可以拟定一个势必而逻辑,每隔5秒录制一段语音,然后进行识别,同时,开启下一段录制,因为识别时间是肯定小于录制时间的,所以能实时识别。这时候,可以用到threading库,为啥不用multiprocessing库呢,首先,录制语音,再识别,不断重复,这就频繁的文件读写了,不停对内存请求,对io接口的请求;而multiprocessing库是用于多核cpu进行计算的,语音录制对cpu占用肯定不大,所以用threading开销小的就行了。
import logging
import time
import wave
import pyaudio
import threading
from rapid_paraformer import RapidParaformer
class ASRService():
def __init__(self, config_path):
logging.info('Initializing ASR Service...')
print("Initializing ASR Service...")
self.paraformer = RapidParaformer(config_path)
def infer(self, wav_path):
stime = time.time()
result = self.paraformer(wav_path)
logging.info('ASR Result: %s. time used %.2f.' % (result, time.time() - stime))
print('ASR Result: %s. time used %.2f.' % (result, time.time() - stime))
return result[0]
def record_audio(filename, duration=5, rate=16000, channels=1):
chunk = 1024
format = pyaudio.paInt16
p = pyaudio.PyAudio()
stream = p.open(format=format,
channels=channels,
rate=rate,
input=True,
frames_per_buffer=chunk)
print("Recording...")
frames = []
for _ in range(0, int(rate / chunk * duration)):
data = stream.read(chunk)
frames.append(data)
print("Finished recording.")
stream.stop_stream()
stream.close()
p.terminate()
wf = wave.open(filename, 'wb')
wf.setnchannels(channels)
wf.setsampwidth(p.get_sample_size(format))
wf.setframerate(rate)
wf.writeframes(b''.join(frames))
wf.close()
def record_and_infer(service, duration, record_event, result_event, wav_path, result_holder):
while True:
# 录音
record_audio(wav_path, duration)
# 通知主线程录音完成
record_event.set()
# 等待主线程处理结果
result_event.wait()
result_event.clear()
# 获取识别结果
result = result_holder['result']
print("Recognition Result: ", result)
def recognize_in_background(service, record_event, result_event, wav_path, result_holder):
while True:
# 等待录音完成
record_event.wait()
record_event.clear()
# 识别音频
result = service.infer(wav_path)
result_holder['result'] = result
# 通知录音线程识别完成
result_event.set()
if __name__ == '__main__':
config_path = 'resources/config.yaml'
service = ASRService(config_path)
duration = 5
wav_path = 'recorded_audio.wav'
record_event = threading.Event()
result_event = threading.Event()
result_holder = {'result': None}
# 启动录音和识别线程
record_thread = threading.Thread(target=record_and_infer, args=(service, duration, record_event, result_event, wav_path, result_holder))
recognition_thread = threading.Thread(target=recognize_in_background, args=(service, record_event, result_event, wav_path, result_holder))
record_thread.start()
recognition_thread.start()
record_thread.join()
recognition_thread.join()发现没有pyaudio库,安装报错
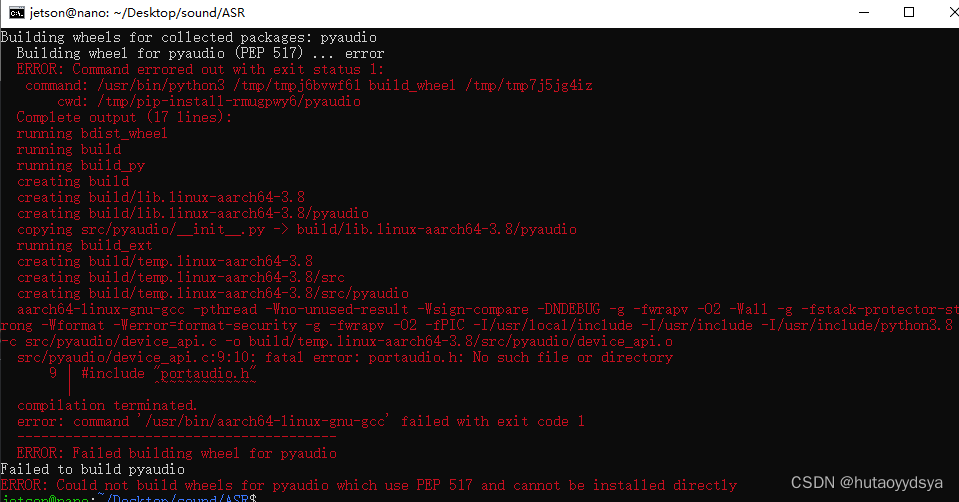
肯定依赖没有装好,安装开发件
sudo apt-get install portaudio19-dev然后重新安装,成功
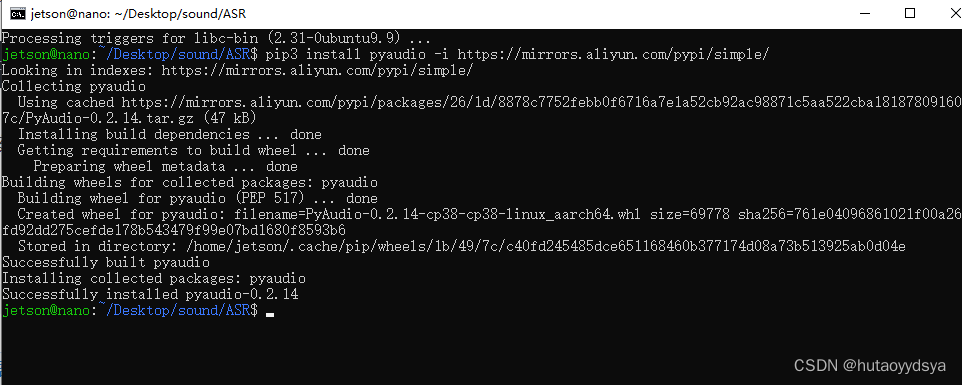
但是识别的时候识别不出麦克风
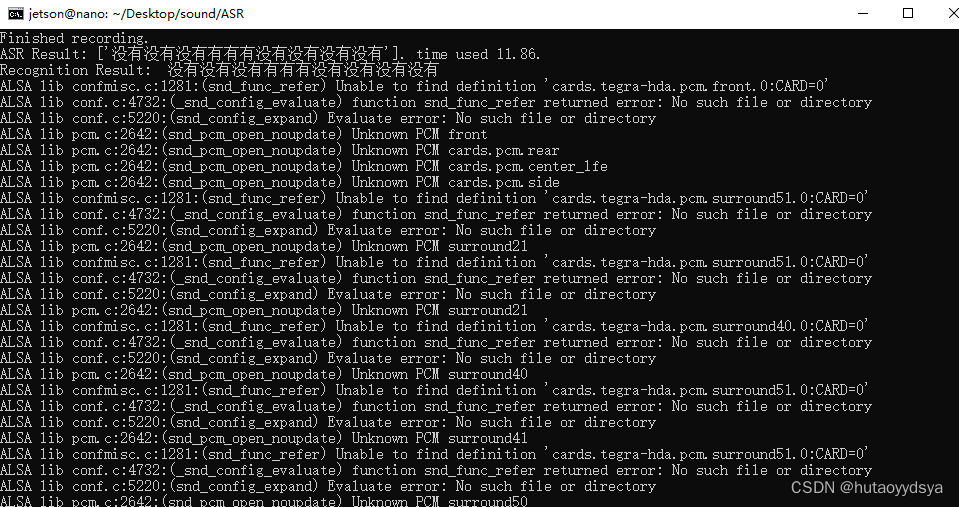
查证,可知安装缺失的ALSA配置文件
sudo apt-get install alsa-base alsa-utils安装后,再运行,成功识别!
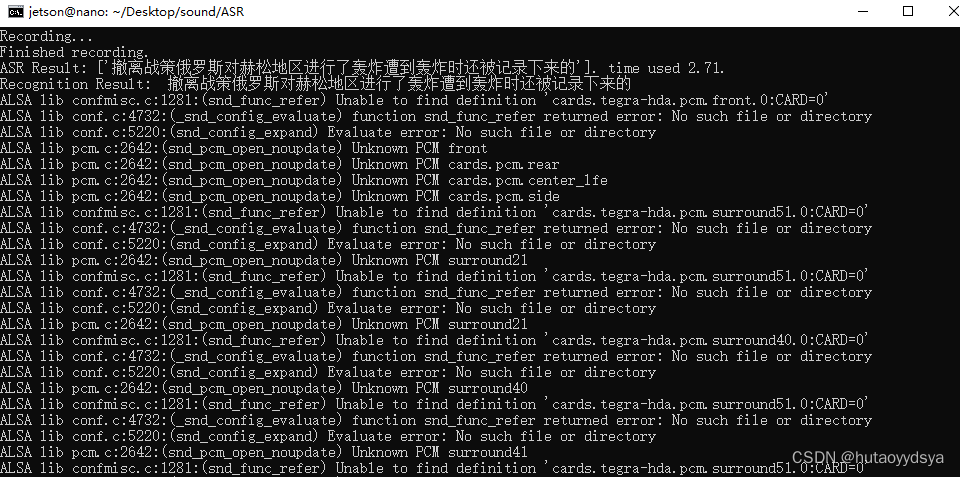
完成!下一步就是联网,自然语言处理,分割。
参考开源:

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)